
Recientemente he estado explorando el mundo HANA de viva voz, hice una instalación de HANA SP9, configure SHINE para validar que tan rápida era la base de datos y tener escenarios de prueba y poder moverme en el entorno para conocerlo un poco más, en las primeras impresiones que me ha dado, poco a poco entiendo los movimientos que se han hecho con el afán de mostrar lo sofisticado de HANA, intentare entrar en detalles de cada uno de los componentes para mostrarles mi experiencia como desarrollador, un detalle en particular con lo que me tope, fue que el sistema rápidamente consumió la memoria del Disco Duro, después de poco más de 1 mes y medio de haber instalado, y como no lo revise en el momento oportuno me topé con el detalle que el LOG había consumido prácticamente el 95% del disco que configure, esto porque al parecer la configuración de mi archivo global.ini no era la más adecuada para mi sistema de pruebas y mientras no hacia Backups constantemente el LOG se extendía día a día consumiendo los recursos de mi sistema a tal grado que me quede sin espacio.
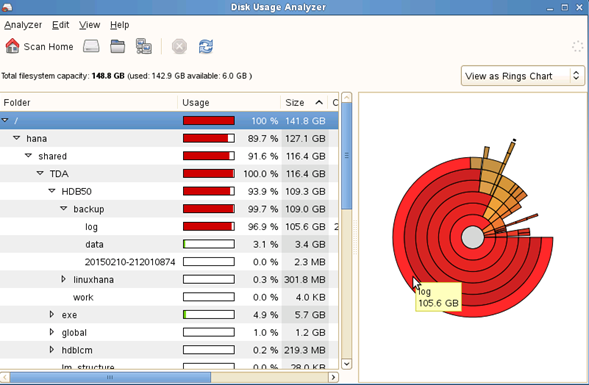
Como se puede apreciar en la imagen la carpeta backup/log es la que contiene el total del disco configurado.
Para corregirlo intente varios métodos, descritos en varios foros y notas de SAP en una de ellas describe cómo mover el LOG a una instancia virtual para posteriormente depurar el log en el sistema y después de esto regresar el archivo a su origen: 1679938 – Log Volume is full
1. Stop the database:
HDB stop
2. Change into the folder mnt00001 of the logvolume (Default: /usr/sap/<SID>/global/hdb/log):
cd /usr/sap/<SID>/global/hdb/log/mnt00001
3. You have to move one of the logvolumes temporarily to another volume where enough space is available. You should free at least 2 GB of space to ensure that the database has enough space to start. To find out the space consumption of each volume execute:
du -sh *
4. Move a volume which consumes at least 2 GB of space (e.g. hdb00003) to a volume with enough free space, e.g. to the data volume (Default: /usr/sap/<SID>/global/hdb/data):
mv hdb00003 /usr/sap/<SID>/global/hdb/data
5. Create a symbolic link to the new folder in the old location:
ln -s /usr/sap/<SID>/global/hdb/data/hdb00003 /usr/sap/<SID>/global/hdb/log/mnt00001/hdb00003
6. Start the database (HDB start) and perform a backup.
7. Wait until log backups are performed.
8. Use the following SQL-Statement to clean up the logvolume:
ALTER SYSTEM RECLAIM LOG;
9. Stop the database again and remove the symbolic link:
rm -f /usr/sap/<SID>/global/hdb/log/mnt00001/hdb00003
El detalle en esto es que no seguí los pasos adecuadamente ya que esta nota hace referencia al LOG pero de sistema no del backup y borre indiscriminadamente archivos del log, lo cual provoco el siguiente error FAIL: proccess hdbdaemon HDB Daemon not running:
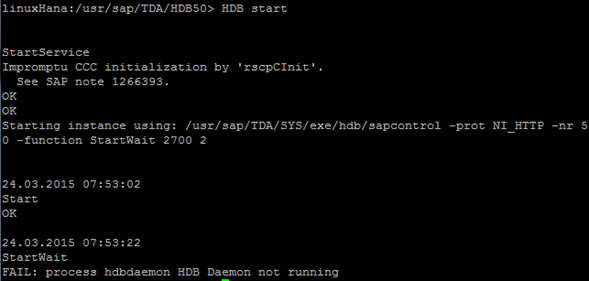
La instancia ya no inicia, para poder revisar el motivo, ya que como se nota en la pantalla no hay mucho detalle en el error específico, es necesario recorrer los directorios de la instalación, cabe mencionar que debemos tener claras algunas cosas para saber que buscar, básicamente la instalación se realiza generalmente en el directorio usr/sap/ listando este directorio tendremos lo siguiente (puede variar dependiendo el nombre asignado al SID y el número de instancia configurado)
linuxHana:/usr/sap> ls -l total 20 drwxr-xr-x 4 root root 4096 Feb 10 22:06 hdbclient drwxr-x--- 4 root sapsys 4096 Feb 10 19:09 hostctrl -rwxr-xr-x 1 root sapsys 211 Feb 10 19:12 sapservices -rwxr-xr-- 1 root sapsys 185 Feb 10 19:12 sapservices_201502_10_19.12.03 drwxr-xr-x 4 tdaadm sapsys 4096 Feb 10 19:11 TDA
En el listado aparece el SID del nombre de nuestra instalación en mi caso TDA, ingresamos y listamos la carpeta:
linuxHana:/usr/sap> cd TDA && ls -l total 8 lrwxrwxrwx 1 tdaadm sapsys 22 Feb 10 19:11 HDB50 -> /hana/shared/TDA/HDB50 drwxr-xr-x 24 tdaadm sapsys 4096 Mar 24 07:58 home drwxr-x--- 3 tdaadm sapsys 4096 Feb 10 19:09 SYS
Ahora aquí es importante identificar para mi caso es HANA SP9 y la organización de carpetas es HDB<número de instancia>, home y SYS, cada una de estas carpetas tiene los archivos que debemos revisar, primeramente el log ubicado dentro de HDB50:
linuxHana:/usr/sap/TDA> cd HDB50 && ls -l total 60 drwxrwxrwx 5 tdaadm sapsys 4096 Feb 22 22:09 backup lrwxrwxrwx 1 tdaadm sapsys 22 Feb 10 19:11 exe -> ../exe/linuxx86_64/hdb -rwxrwxrwx 1 tdaadm sapsys 9559 Feb 10 19:11 HDB -rwxrwxrwx 1 tdaadm sapsys 538 Feb 10 19:11 HDBAdmin.sh -rwxrwxrwx 1 tdaadm sapsys 6015 Feb 10 19:11 hdbenv.csh -rwxrwxrwx 1 tdaadm sapsys 9458 Feb 10 19:11 hdbenv.sh -rwxrwxrwx 1 tdaadm sapsys 1399 Feb 10 19:11 HDBSettings.csh -rwxrwxrwx 1 tdaadm sapsys 1876 Feb 10 19:11 HDBSettings.sh drwxrwxrwx 9 tdaadm sapsys 4096 Feb 10 19:11 linuxhana drwxrwxrwx 2 tdaadm sapsys 4096 Feb 10 19:11 work -rwxrwxrwx 1 tdaadm sapsys 3714 Feb 10 19:11 xterms
En la carpeta linuxhana que es como la nombre en la instalación:
linuxHana:/usr/sap/TDA/HDB50> cd linuxhana/ && ls -l total 44 -rwxrwxrwx 1 tdaadm sapsys 85 Feb 10 19:11 daemon.ini drwxrwxrwx 2 tdaadm sapsys 4096 Mar 24 07:53 lock drwxrwxrwx 5 tdaadm sapsys 4096 Feb 10 21:30 log -rwxrwxrwx 1 tdaadm sapsys 134 Feb 10 19:11 sapprofile.ini drwxrwxrwx 2 tdaadm sapsys 4096 Feb 10 19:15 sec drwxrwxrwx 6 tdaadm sapsys 4096 Mar 21 09:52 tmp drwxrwxrwx 2 tdaadm sapsys 12288 Mar 24 07:53 trace drwxrwxrwx 4 tdaadm sapsys 4096 Feb 10 19:15 wdisp drwxrwxrwx 2 tdaadm sapsys 4096 Feb 10 19:11 work
Aquí encontramos la carpeta LOG donde se almacena el log de la base de datos HANA, así también Trace, para ubicar el trace realizado en cada proceso HANA, me enfocare en revisar en la carpeta trace los últimos realizados para ver cuál fue el error a mayor detalle, para eso usar lo siguiente:
linuxHana:/usr/sap/TDA/HDB50/linuxhana/trace> ls -lrt -rwxrwxrwx 1 tdaadm sapsys 756 Mar 24 07:53 dev_sapstart -rw-r----- 1 tdaadm sapsys 8 Mar 24 07:53 nameserver_linuxhana.35001.stat -rwxrwxrwx 1 tdaadm sapsys 2807 Mar 24 07:53 sapstart.log -rw-r----- 1 tdaadm sapsys 100838 Mar 24 07:53 nameserver_linuxhana.35001.008.trc -rwxrwxrwx 1 tdaadm sapsys 1130503 Mar 24 07:53 nameserver_alert_linuxhana.trc -rw-r--r-- 1 tdaadm sapsys 318 Mar 24 07:53 INSTSTAT -rw-r--r-- 1 tdaadm sapsys 1017 Mar 24 07:53 hdbdaemon.status -rwxrwxrwx 1 tdaadm sapsys 3266430 Mar 24 07:53 daemon_linuxhana.35000.000.trc -rwxrwxrwx 1 tdaadm sapsys 864 Mar 24 08:35 available.log
Aquí devuelve un montón de archivos, para ser más práctico solo pegue los últimos ya que el comando utilizado ordena por fecha más actual, por tanto debo revisar los archivos daemon_linuxhana.35000.000.trc, nameserver_alert_linuxhana.trc y nameserver_linuxhana.35001.008.trc, inicialmente utilizando el comando VI:
linuxHana:/usr/sap/TDA/HDB50/linuxhana/trace> vi daemon_linuxhana.35000.000.trc
Para irme al final del archivo tecleo «G»

Como comentario para los nuevos en Linux para salir de VI presionamos Esc y tecleamos :q! (Salir sin guardar)
En este archivo no encontré nada inusual, pero en nameserver_linuxhana.35001.008.trc
me topé con algo interesante:
[22220]{-1}[-1/-1] 2015-03-24 07:53:10.672982 i Basis ProcessorInfo.cpp(00713) : Using GDT segment limit to determine current CPU ID
[22220]{-1}[-1/-1] 2015-03-24 07:53:10.691693 w Environment Environment.cpp(00295) : Changing environment set SSL_WITH_OPENSSL=0
[22236]{-1}[-1/-1] 2015-03-24 07:53:11.362854 i assign TREXNameServer.cpp(01791) : assign as master nameserver. assign to volume 1 started
[22236]{-1}[-1/-1] 2015-03-24 07:53:11.395670 i FileIO FileStatistics.cpp(00327) : FileFactoryConfiguration::initial(path="/usr/sap/TDA/SYS/global/hdb/backint/", async_write_submit_active=auto,async_write_submit_blocks=new,async_read_submit=off,num_submit_queues=1,num_completion_queues=1,size_kernel_io_queue=512,max_parallel_io_requests=64)
[22236]{-1}[-1/-1] 2015-03-24 07:53:11.396002 i FileIO FileStatistics.cpp(01114) : SubmitQueueConfiguration::initial(path="/usr/sap/TDA/SYS/global/hdb/backint/", num_submit_queues=1,size_kernel_io_queue=512,max_parallel_io_requests=64,min_submit_batch_size=16,max_submit_batch_size=64)
[22236]{-1}[-1/-1] 2015-03-24 07:53:11.397792 i FileIO FileStatistics.cpp(01325) : CompletionQueueConfiguration::initial(path="/usr/sap/TDA/SYS/global/hdb/backint/", num_completion_queues=1,size_kernel_io_queue=512,max_parallel_io_requests=64)
[22236]{-1}[-1/-1] 2015-03-24 07:53:11.399985 i FileIO FileStatistics.cpp(00327) : FileFactoryConfiguration::initial(path="/usr/sap/TDA/SYS/global/hdb/backint/", async_write_submit_active=auto,async_write_submit_blocks=new,async_read_submit=off,num_submit_queues=1,num_completion_queues=1,size_kernel_io_queue=512,max_parallel_io_requests=64)
[22236]{-1}[-1/-1] 2015-03-24 07:53:11.400219 i FileIO FileStatistics.cpp(01114) : SubmitQueueConfiguration::initial(path="/usr/sap/TDA/SYS/global/hdb/backint/", num_submit_queues=1,size_kernel_io_queue=512,max_parallel_io_requests=64,min_submit_batch_size=16,max_submit_batch_size=64)
[22236]{-1}[-1/-1] 2015-03-24 07:53:11.409234 i FileIO FileStatistics.cpp(01325) : CompletionQueueConfiguration::initial(path="/usr/sap/TDA/SYS/global/hdb/backint/", num_completion_queues=1,size_kernel_io_queue=512,max_parallel_io_requests=64)
[22236]{-1}[-1/-1] 2015-03-24 07:53:11.423547 f topology Topology.cpp(00258) : persistence does not exist @ /usr/sap/TDA/SYS/global/hdb/data/mnt00001/hdb00001/
[22236]{-1}[-1/-1] 2015-03-24 07:53:11.425009 f NameServer TREXNameServer.cpp(03323) : persistence initialization failed -> stopping instance ...
[22220]{-1}[-1/-1] 2015-03-24 07:53:11.428356 i Service_Shutdown TrexService.cpp(00781) : Preparing for shutting service down
[22236]{-1}[-1/-1] 2015-03-24 07:53:11.456821 e Basis TREXNameServer.cpp(03353) : Process exited due to an error via explicit exit call with exit code 1 , no crash dump will be written
[22243]{-1}[-1/-1] 2015-03-24 07:53:11.465621 i Service_Shutdown TREXIndexServer.cpp(03782) : Triggering timezone checker shutdown
[22243]{-1}[-1/-1] 2015-03-24 07:53:11.465911 i Service_Shutdown TREXIndexServer.cpp(04024) : Waiting for timezone checker shutdown
[22243]{-1}[-1/-1] 2015-03-24 07:53:11.465983 i assign TREXNameServer.cpp(03062) : shutdown, unassign from volume 1
[22243]{-1}[-1/-1] 2015-03-24 07:53:11.467067 i failover TREXNameServer.cpp(03779) : setinactive(linuxhana) but no failover manager
Si lo notan en linea 19 y 21 me da un poco más de detalle al respecto al parecer algo hice mal que se borró algún directorio requerido, hice una pequeña validación y efectivamente no existía la ruta requerida:
linuxHana:/usr/sap/TDA/HDB50/linuxhana/trace> cd /usr/sap/TDA/SYS/global/hdb/data/mnt00001/hdb00001/ -sh: cd: /usr/sap/TDA/SYS/global/hdb/data/mnt00001/hdb00001/: No such file or directory
Siguiendo con la investigación me tope que era requerido un recovery de la base de datos, afortunadamente hice varios BACKUPS previo este problema, en algunos casos me topé con que algunos otros con este error tuvieron la penosa tarea de reinstalar todo nuevamente, pero espero no sea mi caso, en uno de los manuales de Administración de HANA se explica cómo ejecutar el RESTORE de un Backup desde línea de comandos, utilizando HDBSettings.sh recoverSys.py (link) ya que no puedo levantar la instancia para hacerlo con el SAP HANA Studio.
Primeramente ubicamos el backup al cual deseamos regresar, para eso vamos a la ruta siguiente /usr/sap/TDA/HDB50/backup:
linuxHana:/usr/sap/TDA/HDB50/backup> ls -l total 1248 drwxr-xr-x 2 tdaadm sapsys 4096 Feb 10 21:20 20150210-212010874 drwxrwxrwx 2 tdaadm sapsys 4096 Mar 21 09:42 data drwxrwxrwx 2 tdaadm sapsys 1265664 Mar 21 09:42 log
Aquí se encuentran las carpetas data y log, donde se almacena el backup:
linuxHana:/usr/sap/TDA/HDB50/backup> cd data linuxHana:/usr/sap/TDA/HDB50/backup/data> ls -l total 3560760 -rw-r----- 1 tdaadm sapsys 147456 Mar 21 09:41 COMPLETE_DATA_BACKUP_databackup_0_1 -rw-r----- 1 tdaadm sapsys 88137728 Mar 21 09:41 COMPLETE_DATA_BACKUP_databackup_1_1 -rw-r----- 1 tdaadm sapsys 68972544 Mar 21 09:41 COMPLETE_DATA_BACKUP_databackup_2_1 -rw-r----- 1 tdaadm sapsys 913797120 Mar 21 09:41 COMPLETE_DATA_BACKUP_databackup_3_1 -rw-r----- 1 tdaadm sapsys 2571575296 Mar 21 09:42 COMPLETE_DATA_BACKUP_databackup_4_1
Me gustaría comentar que el proceso es algo tedioso, no sé por qué pero con el usuario tdaadm que es el usuario de administración de la instancia de HANA creada no pude realizar el procedimiento, la idea es recuperar el backup que tenía almacenado, para eso utilizamos el siguiente comando HDBSettings.sh recoverSys.py –command «recover data using file (‘COMPLETE_DATA_BACKUP’) clear log» aquí aclaro que si utilizamos el usuario de sistema tendremos algunos líos al intentar completar la actividad, aquí tratare de resumir, a pesar de ver que tenemos varios archivos solo es requerido COMPLETE_DATA_BACKUP ya que el resto son particiones que el sistema lleva y no es necesario detallarla en el comando, también es necesario pasarse a modo ROOT con el comando su, ubicarse en la carpeta /usr/sap/TDA/HDB50 y ubicar el archivo HDBSettings.sh con el que ejecutaremos el comando requerido, adicional a esto puede haber varios errores en su mayoría cosa de permisos, que con el comando CHMOD podemos arreglar, aquí comento los errores con los que me tope que requirieron algún paso adicional:
2015-03-24T09:36:40-06:00 P027706 0 ERROR RECOVERY RECOVER DAT A finished with error: [448] recovery could not be completed, [2000004] Cannot o pen file «/usr/sap/TDA/HDB50/work/recoverInstance.sql», rc=13: Permission denied
2015-03-24T09:36:40-06:00 P027706 0 ERROR RECOVERY RECOVER DAT A finished with error: [448] recovery could not be completed, [2000004] Cannot o pen file «/usr/sap/TDA/HDB50/work/recoverInstance.sql», rc=13: Permission denied
start system: linuxhana failed: start of nameserver failed
Aquí lo que sucede es que se crea un archivo con el comando mencionado donde se almacena el SQL que se puso entre dobles comillas y generalmente no se definen los permisos pertinentes, esto también puede suceder con diferentes archivos como los propios en la carpeta backup/data en cualquiera de los casos utilizar el comando CHMOD 777 <archivo o carpeta> donde <archivo o carpeta> el mismo error que se presente nos lo mencionara, como el ejemplo anterior «/usr/sap/TDA/HDB50/work/recoverInstance.sql» una vez aclarado esto procedemos a mostrar el comando ejecutado satisfactoriamente:
linuxHana:/usr/sap/TDA/HDB50> HDBSettings.sh recoverSys.py --command "recover data using file ('COMPLETE_DATA_BACKUP') clear log"
[140176928098048, 0.001] >> starting recoverSys (at Tue Mar 24 09:37:49 2015)
[140176928098048, 0.001] args: ()
[140176928098048, 0.001] keys: {'command': "recover data using file ('COMPLETE_DATA_BACKUP') clear log"}
own pid: 27760
recoverSys started: 2015-03-24 09:37:49
testing master: linuxhana
linuxhana is master
shutdown database, timeout is 120
stop system
stop system: linuxhana
stopping system: 2015-03-24 09:37:49
stopped system: 2015-03-24 09:37:49
creating file recoverInstance.sql
restart database
restart master nameserver: 2015-03-24 09:38:04
start system: linuxhana
2015-03-24T09:38:17-06:00 P028165 14c4c6f2400 INFO RECOVERY state of service: nameserver, linuxhana:35001, volume: 1, RecoveryExecuteTopologyAndSSFSRecoveryFinished
recoverSys finished successfully: 2015-03-24 09:38:18
[140176928098048, 28.748] 0
[140176928098048, 28.749] << ending recoverSys, rc = 0 (RC_TEST_OK), after 28.748 secs
Con esto tenemos completado el proceso de restauración y finalmente quedaría hacer la prueba definitiva, ejecutar la instancia y validar que esta volvió a la vida para eso utilizar el usuario de sistema no ROOT y ejecutar el comando:
linuxHana:/usr/sap/TDA/HDB50> HDB start StartService Impromptu CCC initialization by 'rscpCInit'. See SAP note 1266393. OK OK Starting instance using: /usr/sap/TDA/SYS/exe/hdb/sapcontrol -prot NI_HTTP -nr 50 -function StartWait 2700 2 24.03.2015 09:54:05 Start OK 24.03.2015 09:54:15 StartWait OK
Como podemos notar todo fue un éxito y la instancia ha sido recuperada: D
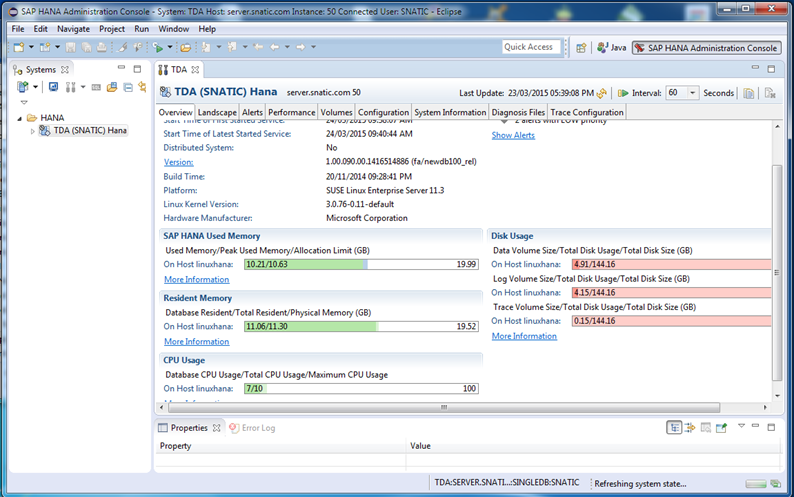
Pero solo es la mitad del camino ya que como se puede notar aún falta recuperar el espacio del disco ya que sigue en estado crítico y solo es cuestión de tiempo a que el LOG me repita el problema, por lo que ahora vamos a pasar a la limpieza, aquí puedo explicar que un tema importante en HANA es el backup, se ofrecen varias formas para sobrellevarlo, sea utilizar arreglos para mover el LOG constantemente, Scripts, y herramientas de terceros, si no tenemos una estrategia clara para esto, tendremos un buen problema a corto plazo, un detalle de HANA es que al ser una base de datos que utiliza la memoria RAM como puente para leer los datos y lograr la máxima velocidad, eso implica como todos sabemos que esta memoria es muy volátil y la perdida de información en ella es muy susceptible, para cuidar esto el sistema realiza el almacenamiento primeramente en LOG y después en la memoria, esto para evitar en lo mayor posible cualquier perdida o error, también a través del log es cómo podemos restaurar el sistema, por lo que es recomendable guardar un par de meses o llevar una buena estrategia para tener puntos de retorno confiables, ahora que ya tenemos la instancia prendida y operando, es posible analizar este detalle utilizando el SAP HANA Studio, no mas terminal de momento, primeramente debemos ir a la sección de Backup, para eso conectarse con SAP HANA Studio y dar doble clic en la sección de BACKUP:
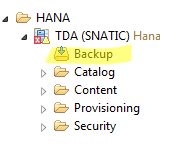
Aquí se puede notar el último Backup:

Si pasamos a la sección Backup Catalog y presionamos el checkbox Show Log Backups tendremos lo siguiente:

Aquí si se nota tengo un pequeño dilema, muchos archivos de log que están en rojo, aquí puedo borrarlos utilizando las posiciones de Data Backup, lo más pertinente es revisarlos todos y determinar cual ya no requiero, en este caso solo busco optimizar el espacio por lo que buscare el que más espacio me libere y borrare ese.

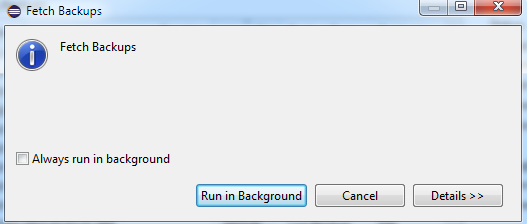

Esta opción nos dará una lista lo recomendable es bajarla y analizarla para evitar borrar algo que necesitemos:
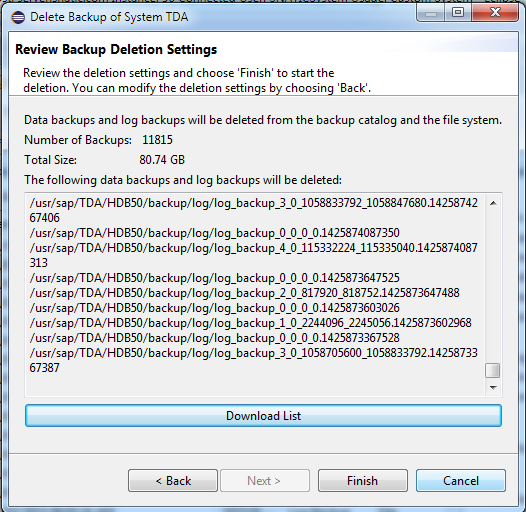
Ya solo quedaría dar Finish y revisar el resultado final.
Bueno después de repetir este procedimiento para los diferentes backups que ya no requiero, mi sistema se ha rehabilitado en espacio y después de esto tendré que diseñar algún mecanismo que me ayude a borrar este tipo de procesos.
Solo para complementar en el mismo SAP HANA Studio en la sección de Configuration
Podemos ubicar la configuración del backup, y los periodos a los que se almacena en automático, un parámetro importante a tener en cuenta es log_backup_timeout_s este determina el intervalo de tiempo que se almacena el log en el sistema esto si nuestro backup está en modo NORMAL (opciones: NORMAL «En este modo el backup se realiza constantemente cerca de que este llegue al punto definido en log_segment_size_mb y de la misma forma se almacena el backup automaticamente», OVERWRITE «Aquí no se realiza backup y el segmento es liberado en cada tamaño definido» y LEGACY «No se hace backup y se liberan los segmentos hasta que se realiza un backup completo») a través del parámetro log_mode determinamos este modo.

Otro parámetro importante es enable_auto_log_backup ya que en el modo NORMAL indica que se realizara el backup de manera automática por lo que si lo cambiamos a NO podremos evitar la saturación en el disco, también mencionar que me pareció un excelente detalle el Filtro puesto para ubicar los parámetros, ayuda mucho a ubicarse, por ejemplo solo al poner log encuentras lo que necesitas relevante al log:
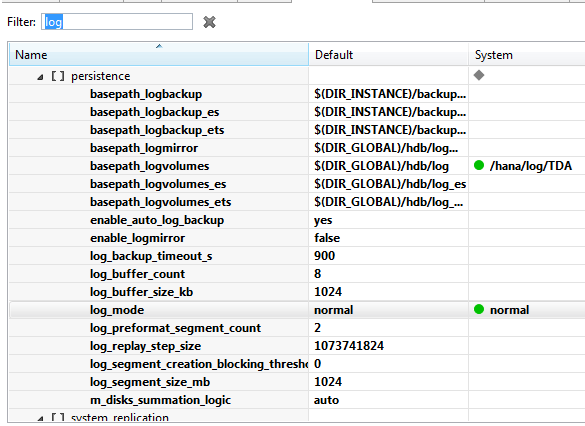
Espero le sirva a alguien este tutorial y le facilite la vida recuperando la instancia HANA.